상식 밖의 데이터 조작 사기
상식 밖의 데이터 조작 사기
2022년 8월 중순은 이에 대한 디스커션으로 아주 난리였다. 짧게 요약하면, 전세계적으로 유명한 심리학자이자 행동경제학자인 댄 애리얼리(Dan Ariely)와 공저자들의 연구가, 너무 저열한 방식의 데이터 조작으로 만들어졌다는 게 밝혀졌고, 페이퍼는 철회됨.
자세한 리포트는 이 링크를 따라가면 됨.
뉴욕타임즈 베스트셀러인 “상식 밖의 경제학”(영문제목 Predictably Irrational)로 유명한 댄 애리얼리(Dan Ariely)와 공저자들은 2012년에 Dishonest self-report를 줄이는 방법에 관한 연구를 출판했는데, 자동차 보험 가입시, Honesty statement(“이 양식에 기입한 모든 정보는 최선을 다해 정확하게 기입한 내용임을 서약합니다”라는 곳에 이름을 쓰고 서명하는 것)를 서류 맨 앞에 놓으면, 서류 맨 뒤에 놓는 것보다, self-report하는 mileage가 유의미하게 늘어난다는 것을 보고하고, 사소한 디자인의 차이가 guilty aversion을 잘 trigger 했다는 식으로 해석했었다.
그런데 왠걸. 위 연구를 replicate한 결과가 같게 나오지 않는다는 리포트 이후에, 몇몇 연구자들이 원 데이를 확인다가 여러 가지 이상한 걸 발견했다. 우선 가장 눈에 띄는 데이터의 비정상성은, 마일리지 리포트가 “너무 균일”하다는 거다.
데이터를 보기 전에, 한 나라의 모든 차들이 1년 동안 주행하는 거리를 상상해보자. 주행거리가 아주 짧은 소수의 차가 있을 거고, 다른 소수의 차는 주행거리가 아주 길거고, 나머지 차들은 적당한 주행거리를 가질 거니까, 주행거리의 히스토그램을 그리면 양쪽 끝이 작고 가운데가 높은 종 모양의 형태를 가질 거다. 아래 그림 같은거다.
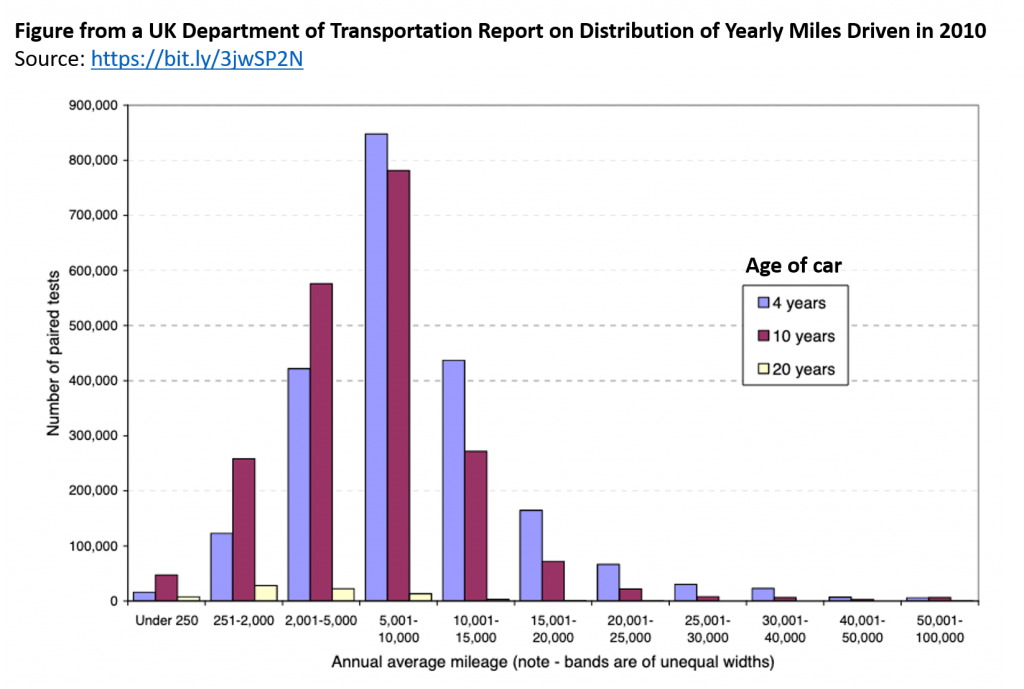 [출처: UK Department of Transportation. datacolada.org/98 에서 인용된 자료를 재인용]
[출처: UK Department of Transportation. datacolada.org/98 에서 인용된 자료를 재인용]
근데 조작된 데이터는 아래와 같이 생겼다….
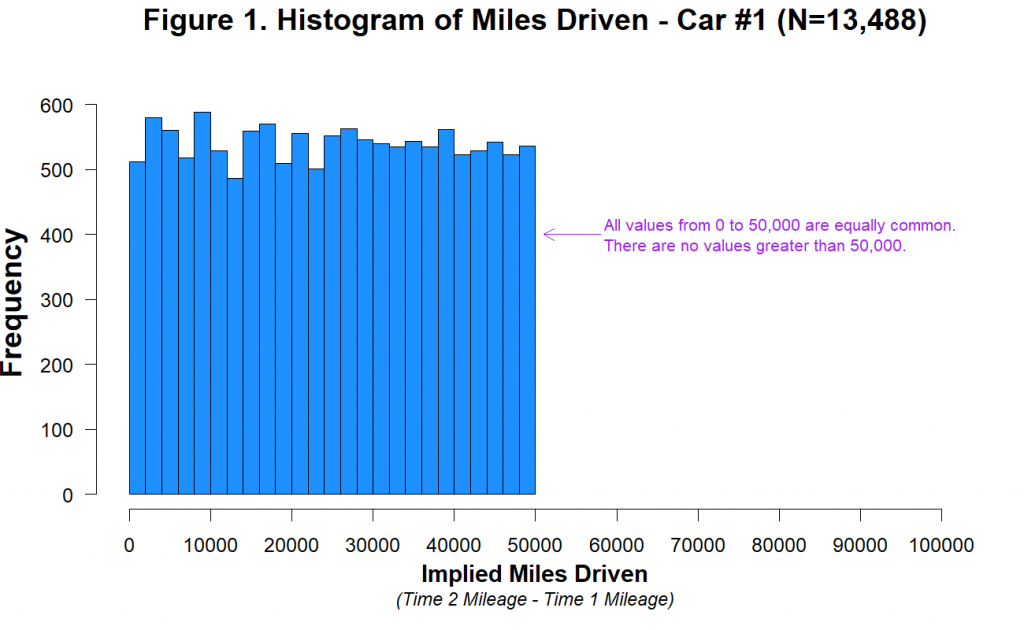 [출처: datacolada.org/98]
[출처: datacolada.org/98]
RANDBETWEEN(0,50000)로 위와 같은 수의 데이터를 생성한다음 그걸 도수분포표로 찍으면 아래와 같다.
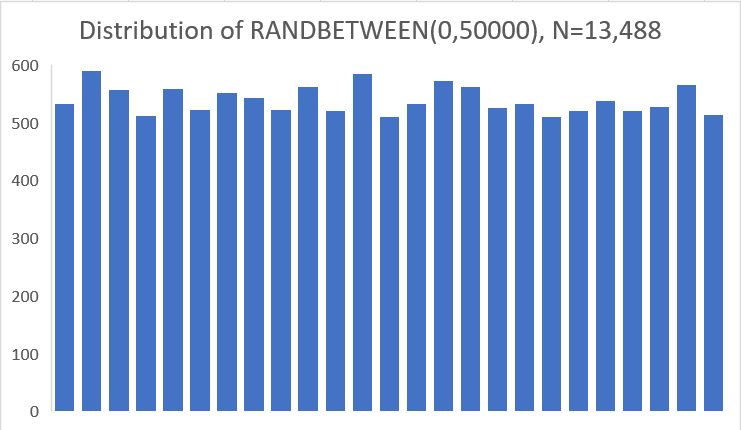
통계적인 분석을 엄밀히 보일 필요도 없이, 랜덤하게 생성된 데이터의 도수분포표와 연구에 쓰인 자료의 도수분포표가 비슷하다는 걸 알 수 있다. 이것 말고도 여러가지 데이터상에서 자연적으로 얻어진 데이터라고 하기에 이상한 점 (“1년 주행거리가 얼마나 되나요?”라는 질문을 받으면 ‘9,000킬로’나 ‘14,000킬로’처럼 끝자리수를 반올림하여 0으로 부르는 경향이 큰데, 저 수상한 데이터에는 모든 끝자리가 균등하게 발견된다.)을 보고했으니 관심있으면 위에 링크에 가서 확인해보면 좋을 듯.
이미 위 두 개의 너무 이상한 데이터의 특징만으로 데이터에 조작 가능성은 너무 명확해서 철회될 가능성이 높지만 (업데이트: 2022년 9월 13일에 철회결정됨), 그것 말고도 재밌는 걸 발견했다. 엑셀 데이터에 폰트가 두 개 쓰였는데, 한 개의 폰트 데이터(X라고 하자)를 모아서 정렬하고, 다른 폰트 데이터(Y라고 하자)를 모아서 정렬해 봤더니, 정확히 Y=X+RANDBETWEEN(0,1000)처럼 보인다는 것이다. 즉, 데이터 셋 하나를 조작해서 만들어 놓고, 데이터를 두 배로 만들기 위해 각 데이터값에 0에서 1000사이의 랜덤한 값을 더해서 새 데이터를 만들었다는 거다.
댄 에리얼리는 데이터 조작을 부정했고, 자기도 몰랐던 일이라고 성명서를 냈다. 웃긴건, 그 성명서에도 폰트가 두 개라는 거다. 나는 여기에 어떠한 추가 코멘트도 남기지 않겠다만, 소설가는 좋은 상상을 할 수도 있을지 모른다.